1.目的和意义
自动摘要技术已经得到了广泛的应用,规范合理的评价标准可以促进自动摘要技术的发展。但同时,自动摘要评价方法也是最具争议的,至今仍面临着许多挑战。
首先,人工评价成本高、耗时长,并且主观性强,一直以来很难对自动摘要系统开发提供切实有效的帮助,研究者更倾向于可以客观高效地进行自动摘要的自动评价方法。其次,有时摘要系统生成了一篇很好的摘要,却与作为评价标准的人工摘要相差甚远,给摘要评价带来了很大的困难,因此人工标准摘要的公平性也是自动摘要评价方法研究的一个难点。第三,摘要系统通常按照不同的压缩率来生成相应摘要。在不同压缩率下,摘要包含的原文档中的信息量是不同的。如何在评价中反映这一变化,也增加了自动评价的难度和复杂性。最后,摘要通常是面向需求的,应该根据用户或应用的需求包含特定的信息。如何在进行评价时也对用户或应用的需求加以考虑,这也使自动评价变得更加复杂。
2.自动摘要评价分类
自动摘要的评价方法主要分为两大类,分别是内部评价方法和外部评价方法。
内部评价方法主要包含以下五个准则,分别是:
信息量:该标准评测系统摘要是否包含、 包含多少原文的重点要点等关键内容。通过与参考摘要比较, 评测摘要内容所含的信息量,也就是系统摘要对参考摘要的信息覆盖程度。
连贯性:各语句间是比较相关,内容连贯一致,上下句通顺,还是各句间内容上脱节, 不连贯甚至语无伦次。有些抽取型摘要是将原文中不同位置的语句提取出来,将文档分割剪切粘帖而成,因此在语义衔接和逻辑上必将出现不连贯的问题,即便是理解型摘要也会有不连贯的问题,尤其是采用自然语言生成技术。连贯性可以由专家主观衡量,也可以通过对语法,书写风格,语句的完整性,连接词逻辑关系等方面进行评估。
可读性:可读性在一定程度上是与连贯性相通的。可以从很多方面来衡量摘要的可读性, 比如拼写与语法的正误,是否清楚地突出文章主旨等。
长度:摘要长度与信息量有一定的关系,摘要越长则其包含的信息量就可能越多。一般情况下,参考摘要的长度是随机的,摘要系统生成的摘要如果没有严格限制长度,那么摘要长度也是随机的。同一个摘要系统的性能随着其产生的摘要长度的不同会有很大的变化。
冗余度:冗余度是评测摘要包含的信息内容是有重复,是否保证摘要的简洁特性。如果只追求信息覆盖量,使摘要过长,则会出现叙述繁杂或存在大量相同意义语句等。
外部评价方法是一种间接评价方法,将摘要应用于某一个特殊的任务中,根据摘要完成这项任务的效果来评价自动摘要系统的性能。比如11998年,美国国防部高级研究计划署在TIPSTER文本计划项目下进行了一次自动摘要系统测试,具体方法是对TREC文本集的每篇文章生成摘要,然后根据摘要对原文章进行分类,将分类的准确度作为评价标准。
3.ROUGE评价方法
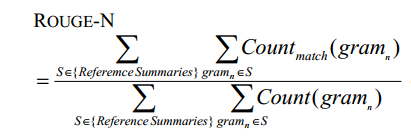
ROUGE评价准则是Chin-Yew Lin于2004年提出。ROUGE评价方法的基本思想是由多个专家分别生成人工摘要,构成标准摘要集。将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过多专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标准之一。
3.1 ROUGE-N:N-gram Co-Occurrence Statistics
句子T由词序列W1,W2,W3,…Wn组成的,那么句子T出现的概率为
P(T)=P(W1,W2,W3,…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
参数空间过大,不可能实用化;数据稀疏严重。
引入马尔科夫假设:
一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。
N-gram模型认为第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关。整句的概率就是各个词出现概率的乘积。
P(T)=P(W1,W2,W3,…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2)P(W3)…P(Wn)
P(T)=P(W1,W2,W3,…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
P(T)=P(W1,W2,W3,…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|Wn-2Wn-1)
3.2 ROUGE-L:Longest Common Subsequence
序列X = [x1, x2, …, xm]
序列Z = [z1, z2, …, zn]
如果X中存在一个下标严格递增的子序列[i1,i2 …, ik], 使得所有的xij= zj (j=1,2,…,k).则称Z是X的子序列。
LCS:给定序列X、Y,使得公共子序列长度最大的序列为两者的最长公共子序列。
摘要X为参考摘要,长度为m;摘要Y为候选摘要,长度为n。以F值来衡量摘要X,Y的相似度。
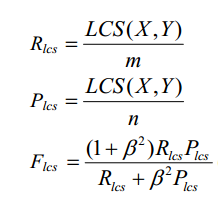
将LCS应用到摘要级时,对参考摘要中的每一个句子ri 与候选摘要中的所有句子比对,以union LCS作为摘要句ri 的匹配结果。给定参考摘要X包含u个句子m个词,候选摘要Y包含v个句子n个词,那么Summary-level的LCS计算公式如下:
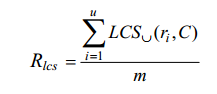
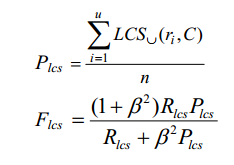
3.3 ROUGE-W:Weighted Longest Common Subsequence
引入加权系数W=连续匹配的最长公共子串长度
WLCS = W * LCS
为使连续匹配比不连续匹配赋予更大的权重,公式描述如下
![]()
![]()
同时为了归一化最终的ROUGE-W值,通常选择函数与反函数具有相似形式的函数。
3.4 ROUGE-S:Skip-Bigram Co-Occurrence Statistics
Skip-bigram is any pair of words in their sentence order, allowing for arbitrary gaps.
S1. police killed the gunman.
S1中的Skip-bigram有:police killed、police the、police gunman、killed the、killed gunman、the gunman.
给定参考摘要X,长度为m;候选摘要Y,长度为n。
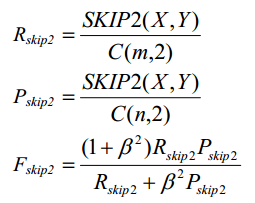
Skip2(X,Y)表示候选摘要与参考摘要的skip-bigram匹配次数。
4.参考文献
[1]Lin C Y. Rouge: A package for automatic evaluation of summaries[C]//Text Summarization Branches Out: Proceedings of the ACL-04 Workshop. 2004: 74-81.
[2]张瑾, 王小磊, 许洪波. 自动文摘评价方法综述[J]. 中文信息学报, 2008, 22(3): 81-88
[3]刘茵, 李弼程. 自动文摘系统评测方法的回顾与展望[J]. 情报学报, 2008, 27(2): 235-243.
林萌
2015.01.17
原创文章,作者:BFS,如若转载,请注明出处:https://www.isclab.org.cn/2015/01/18/%e8%87%aa%e5%8a%a8%e6%91%98%e8%a6%81%e8%af%84%e4%bb%b7%e7%b3%bb%e7%bb%9f/