首先我们应该明白什么是生成模型和判决模型,生成模型是指我们要求具体的概率模型,主要是求联合概率密度函数,然后对联合概率表达式里的各个参数进行估计;而判决模型目标是求条件概率,找到正负样本的分类边界。常见的属于生成模型算法有朴素贝叶斯模型,隐马尔科夫模型,EM算法,高斯混合模型等;常见的属于判决模型的算法有SVM,线性回归,对数回归,条件随机场,BP神经网络等。而EM算法就是生成模型的一种。
1 MLE(最大似然估计)
最大似然估计是通过样本集来估计总体分布的参数,以期使得指定样本集产生的概率最大。最大似然估计的原理很简单:
(1) 写出似然函数;
(2) 整理出对数似然函数;
(3) 求偏导,令倒数为零,得到似然方程;
(4) 解似然方程,得到的参数估计即为所求。
但是最大似然估计有它的不足之处,就是当已知样本中包含隐藏变量的时候,最大似然估计就无效了。然而很多时候,我们又不得不面临包含隐藏变量的问题。怎么办?EM算法应运而生了。最初是由Ceppellini等人1950年在讨论基因频率的估计的时候提出的,后来被Hartley和Baum等人发展的更加广泛,其实目前引用较多的是1977年Dempster等人的工作。
在具体讲EM的原理之前,首先要想一想以下几个问题:
1. EM用来解决什么问题?
2. 为什么叫Expectation和Maximization?
3. 为什么EM能够解决问题?
2 EM算法原理
其实EM算法的思想很简单,就是两步,E步和M步,但时想要真正明白EM算法的整个过程,就必须搞清楚他的整个公式推导,而公式推导的过程却是比较复杂的。
2.1 E步
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与最大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?
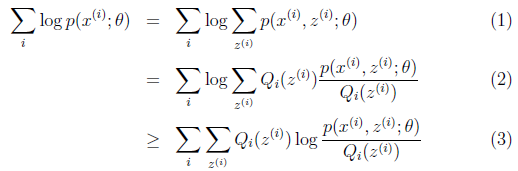
本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解,注意这里z也是随机变量。对每一个样本i的所有可能类别z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量x的边缘概率密度),也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。那OK,我们可否对(1)式做一些改变呢?我们看(2)式,(2)式只是分子分母同乘以一个相等的函数,还是有“和的对数”啊,还是求解不了,那为什么要这么做呢?咱们先不管,看(3)式,发现(3)式变成了“对数的和”,那这样求导就容易了。我们注意点,还发现等号变成了不等号,为什么能这么变呢?这就是Jensen不等式的大显神威的地方。
根据Jensen不等式等号成立的条件,可知当等号成立时,有
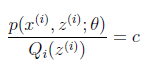
由于分母求和等于1,进一步推导有:
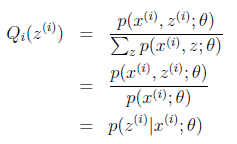
这样我们就可以首先初始化θ,然后通过上式计算z的概率密度分布,再代入到(3)式,便得到一个只含有待估计参数θ的似然函数。这就是我们所说的E步,E步的任务就是通过初始化的θ计算Q_i (z^((i) ) ),然后进一步得到期望函数。
2.2 M步
得到期望函数之后,我们就可以通过利用最大似然估计的方法来求参数θ估计值
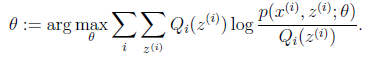
然后把新的θ估计值代入到E步对Q_i (z^((i) ) )进行更新,这样不断的进行迭代直到收敛为止。收敛条件既可以通过θ来控制,也可以通过Q_i (z^((i) ) )来控制。
2.3 Jensen不等式
其实关于凸函数和凹函数,国际上和或内有时候并不是很一致,这里我们以Jensen不等式为准。对于一元函数,如果其二阶导数大于等于零,则说明其实凸函数;对于多元函数,如果其Hessian矩阵是正定或者半正定的,则说明其是凸函数。对于凸函数有E[f(X)]>=f(E[X]),对于凹函数,有E[f(X)]<=f(E[X]),而等号成立的条件就是当自变量x是常数,这里不再多说了。
2.4 EM算法为什么能收敛
那么究竟怎么确保EM收敛?假定θ^((t))和θ^((t+1))是EM第t次和t+1次迭代后的结果。如果我们证明了l(θ^t )≤l(θ^((t+1)) ),也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定θ^((t))后,我们得到E步:
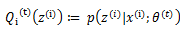
然后进行M步,固定Q_i (z^((i) ) ),并将θ^((t))视作变量,对上面的l(θ^t )求导后,得到θ^((t+1)),这样经过一些推导会有以下式子成立:
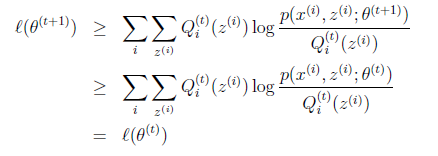
则可以说,每一次迭代都是单调增加的,我们可以选择两次的θ满足一定的阈值是认为迭代达到收敛。
2.5 EM算法总结
不知道最初提出的三个问题大家明白了没有?
1.EM算法用来解决什么问题?
包含隐藏变量的最大似然估计
2.为什么叫Expectation和Maximization?
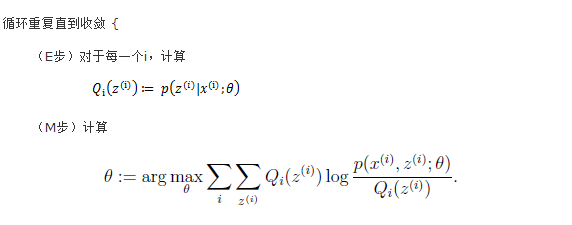
3.EM算法为什么能够解决问题?
因为EM算法迭代的每一步都是单调的,只需要控制迭代的结束条件。
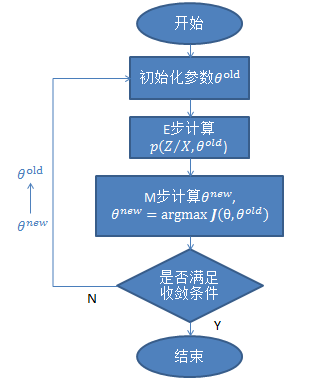
可以将EM算法的整个过程整理成流程图如下:
3 EM算法应用
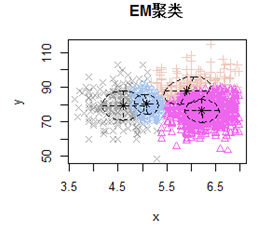
经过上面对算法原理的剖析,我想大家应该对EM算法有了一个比较深入的了解。EM算法有很多应用,常见的像GMM高斯混合模型,EM聚类,HMM隐马尔科夫等。这里说一下EM聚类,EM聚类和K-means聚类的相似点是两者都需要设置初始质心,都利用的是EM算法的思想,但是K-means属于硬指定(一般通过欧氏距离),而EM属于软指定(通过计算到不同质心的概率),下图就是用EM做的一个简单的聚类实验得到的聚类结果:
以上所写内容主要是通过学习一些大牛的文章或者书籍总结的,难免有一些不足之处,希望大家批评指正。
4 参考资料
《Pattern Recognition And Machine Learning》
《Maximum likelihood from incomplete data via the EM algorithm》
http://blog.csdn.net/zouxy09/article/details/8537620
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/21/2603020.html
http://www.cnblogs.com/lifegoesonitself/archive/2013/05/19/3087143.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
刘旭东
2014.12.02
原创文章,作者:BFS,如若转载,请注明出处:https://www.isclab.org.cn/2014/12/01/%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e5%8d%81%e5%a4%a7%e7%bb%8f%e5%85%b8%e7%ae%97%e6%b3%95%e4%b9%8bem%e7%ae%97%e6%b3%95-3/